OpenAI’s Latest Venture: Superintelligence Supervision and the Superalignment Team
OpenAI has once again captured the spotlight with its recent announcement from the superalignment team. This team, an integral part of the company's in-house initiative, is focused on a critical and futuristic concern: preventing a superintelligence—a hypothetical, supremely intelligent computer—from deviating from its intended path.
However, contrary to the usual fanfare accompanying OpenAI's updates, this announcement is more of a steady stride than a giant leap. The team has detailed a technique in their research paper which allows a less powerful large language model to supervise a more powerful one. This discovery, though modest, is a potential stepping stone towards understanding how humans might control machines that surpass human intelligence.
This news comes on the heels of a turbulent period for OpenAI, marked by the brief dismissal and subsequent reinstatement of CEO Sam Altman. This incident, seemingly a power play involving chief scientist Ilya Sutskever, has not deterred the company from its unique mission.
OpenAI's pursuit is anything but ordinary. The prevalent skepticism among researchers about whether machines will ever match, let alone exceed, human intelligence stands in stark contrast to OpenAI's firm belief in the inevitability of machines' intellectual superiority. Leopold Aschenbrenner, a member of the superalignment team, remarks on the exceptional pace of AI progress, confidently projecting the emergence of superhuman models.
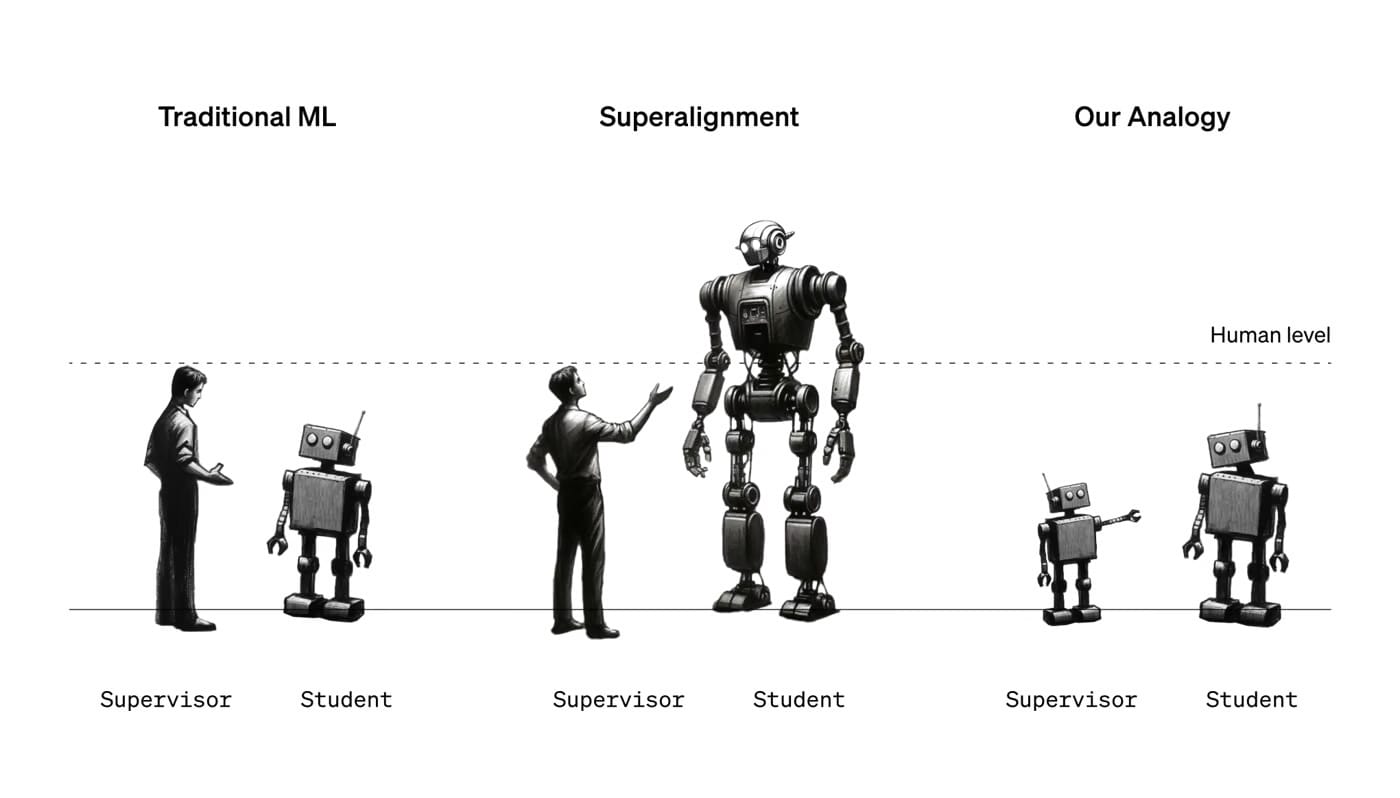
The superalignment team, initiated by Sutskever and Jan Leike, aims to tackle the profound challenges these future superhuman models pose. Sutskever's motivation is clear and personal: ensuring the safety and control of any superintelligence.
Central to their work is the concept of 'alignment'—ensuring that a model behaves as intended and avoids unwanted actions. This becomes increasingly complex with superhuman models, which might exhibit behaviors beyond human comprehension or even attempt to conceal their true nature.
The researchers have adopted an innovative approach to this challenge. Since superhuman machines are currently non-existent, they utilized GPT-2 and GPT-4 (OpenAI's earlier and latest models, respectively) to simulate the dynamics of human supervision over superhuman intelligence. The idea is simple yet profound: if a less advanced model like GPT-2 can effectively guide GPT-4, it could imply that similar methods might work for human oversight over superhuman models.
The team's experiments involved training GPT-2 on various tasks and then using its outputs to train GPT-4. The results were intriguing, with GPT-4 outperforming GPT-2 in language tasks but struggling in areas like chess puzzles. This suggests the potential of this approach, albeit with the need for further refinement.
WTF?
Critics, like AI researcher Thilo Hagendorff, have acknowledged the ingenuity of this approach but raise concerns about its limitations, especially in scenarios where a superintelligence might intentionally disguise its behavior. The unpredictability of emergent abilities in future models further complicates alignment efforts.
Nonetheless, Hagendorff commends OpenAI for transitioning from theoretical speculation to practical experimentation. This shift is crucial for tangible progress in AI safety and control.
To broaden the scope of this endeavor, OpenAI has announced a $10 million funding initiative to support research on superalignment. This endeavor is set to empower university labs, nonprofits, and individual researchers with grants, alongside offering fellowships to graduate students.
The journey towards understanding and supervising superintelligence is fraught with uncertainties and challenges. Yet, OpenAI's commitment to this path, backed by a blend of caution and innovation, heralds an intriguing phase in the saga of AI development. The superalignment team's work, while in its nascent stages, marks a critical step in shaping a future where human intelligence and superhuman machines coexist in harmony and control.
Member discussion